最近去自強工業科學基金會上「Python網頁資料擷取與分析班」
這個是政府有補助的職訓課程,講師是吳清輝老師
如果全程參與,在課程結束之後會補助/退費 80%
也就是自己負擔 20%,感覺蠻划算的
總共有10週/次的課程
課程內容跟之前在東吳上的課程相比較,算是進階課程
也就是直接從python抓取資料開始
課程進度/內容
1.資料處理能力,CSV與JSON讀取與寫入
2.資料處理能力,XML與SQLite資料庫讀取與寫入
3.網頁資料擷取與轉換Python存取網站方式
4-1.網頁資料擷取
4-2.轉換BeautifulSoup模組
5-1.資料分析能力
5-2.NumPy模組
6.資料分析能力Pandas模組
7.資料視覺化能力各種圖表之呈現
8.資料視覺化能力圖表繪製其他技巧
現在資料科學算是很熱門的議題
可以處理資料的方式很多種,python是其中一種
想說有人帶入門是比較快的學習方式
之後會把每週的筆記整理PO上來
第一次上課的主要內容
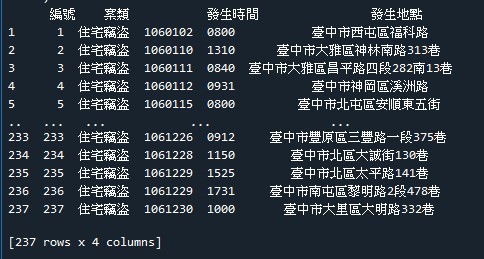
_用requests下載資料臺中市住宅竊盜資訊
_用檔案物件儲存為CSV檔案
_用pandas產生DataFrame與輸出Excel檔
使用的資料是來自政府公開資訊網
所以直接用requests模組就可以抓取資料
可以透過file模組存成csv 或 txt檔等文字檔 或者二進制文件
備註:
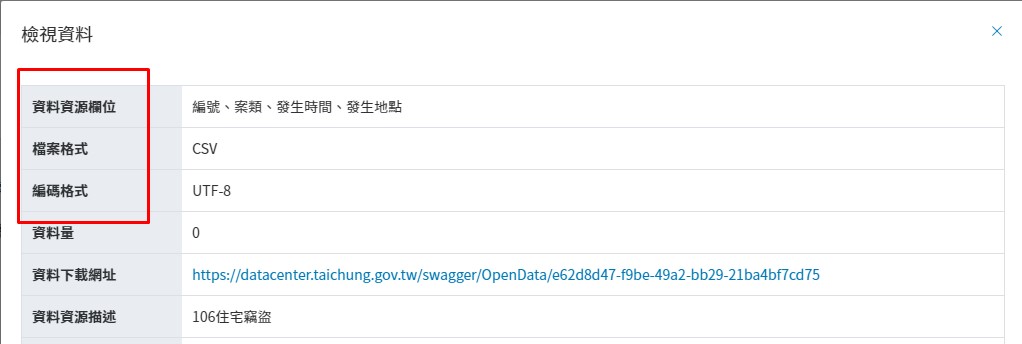
1.取得資料的時候要注意資料的檔案格式、編碼格式,存檔的時候也要儲存為相同的格式
2.如果要轉存成其他形式的檔案,還要注意資料的欄位
下面的程式碼就是直接取得政府開放資料的csv檔,並且儲存成相同格式與編碼的檔案
資料來源:臺中市住宅竊盜資訊
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import requests import pandas as pd html = requests.get("https://datacenter.taichung.gov.tw/swagger/OpenData/e62d8d47-f9be-49a2-bb29-21ba4bf7cd75") html.encoding="utf-8-sig" #多了\ufeff "utf-8" --> "utf-8-sig" #print(html.text) #切割換行 list1=html.text.split("\r\n") #print(len(list1)) # 239 #print(list1[0]) #print(list1[0].split(",")) #['編號', '案類', '發生時間', '發生地點'] cols = list1[0].split(",") data= [] for i in range(1,len(list1)-1): list2=list1[i].split(",") list2[3]=list2[3].strip(" ") data.append(list2) #print(data) index=[] for i in range(1,len(list1)-1): index.append(i) #print(index) df = pd.DataFrame(data,index,cols) print(df) df.to_excel("住宅竊盜_0809.xlsx") |
備註:
html.encoding="utf-8-sig" #多了\ufeff "utf-8" --> "utf-8-sig"
因為檔案是用uft-8-sig編碼,文件會有 BOM 訊息,輸出的時候第一列前面會有\ufeff
不過有時候又會沒有,不知道是不是檔案更新的關係
轉存的結果

在spyder的控制台也可以看到輸出