最近將講師預錄的研習簡報影音檔上傳到youtube
試著使用語音辨識產生字稿,替影片加上字幕
雖然只有20分鐘上下的影片,整個後製還是至少會花掉至少一個工作天;由於搭配使用了不少軟體,趁這個機會把工作流程記錄下來
◎音檔處理
GoldWave
雖然是試用版軟體,但好像沒有特別的使用限制
處理風切聲之類的雜訊、單獨出現的爆音、音量不平均的情況,如果是收音設備本身的噪音就沒辦法處理得很好,會失去原本的音質
◎影音轉檔
使用youtube的格式
上傳到youtube之後再下載,避免因為不同影片格式的不同幀數,造成影音時間的誤差,這對字幕檔的時間記錄影響非常大
而且之後也是要上傳到youtube平台,所以乾脆直接用youtube轉檔過的影音檔來進行語音辨識
◎字稿
pyTranscriber
免費的開源程式,結合google chrome語音辨識-Web Speech API(所以必須連上網路)+字幕檔/純文字檔輸出的python程式,這是目前我覺得最快的方式
也是可以透過google文件+語音輸入+虛擬音源線軟體,來產生字稿。原理是透過虛擬音源線模擬麥克風輸入,配合google文件的語音輸入功能
缺點是電腦不能做別的事,影像檔有多久就要跑多久;另外網路上也有網頁板模式,但是缺點一樣,影像檔多久就需要多久的轉換時間
而且而且,這些都是用google的語音辨識,所以就選擇轉換效率最高的pyTranscriber
備註:
線上檔案語音轉文字字幕:Web Speech to Text / Speech recognition with Google Chrome: Web Speech to Text
◎字幕檔編輯
Aegisub
免費的開源程式,可以透過音訊頻譜或波型,視覺化的方式調整音訊與字幕文字檔的位置
因為pyTranscriber的斷句是依據語音的間隔,如果說話者斷句不太自然、太多贅詞、語氣詞,就會造成斷句不正常,必須要適當/手動斷句
SrtEdit
也是編輯字幕檔的程式,但只能開啟影音檔,所以我只是用來另存字幕檔格式,將ass檔轉成srt檔
原因是在Aegisub如果新建字幕檔,或者是讀取純文字檔等方式來編輯字幕檔,只能存成ass檔,而youtube不支援ass格式字幕檔
Notepad++
開啟ass檔、srt檔進行文字調整,如果只是改錯字,用Notepad++比較快
◎影音合併
FormatFactory
合併重新編輯的音源檔與原始影音檔,也可以用來嵌入字幕檔
◎流程
1.GoldWave可以直接載入影音檔,處理音源問題後另存音訊檔(例如:wav格式)→
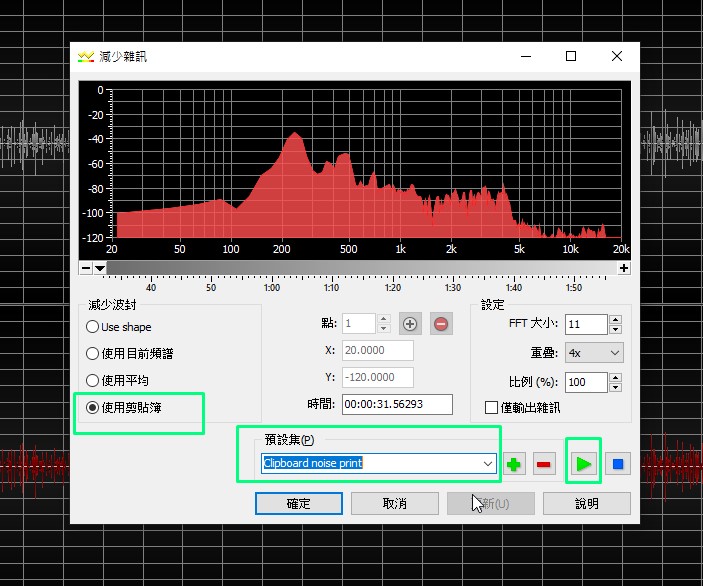
1)減少雜訊
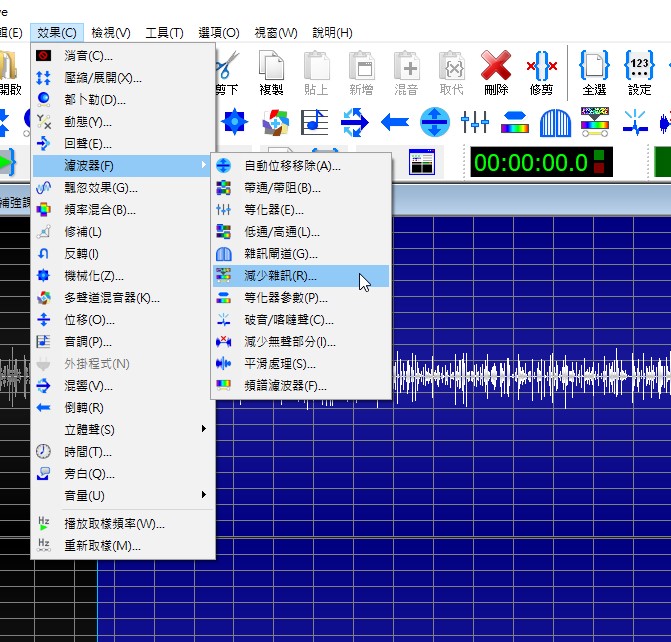
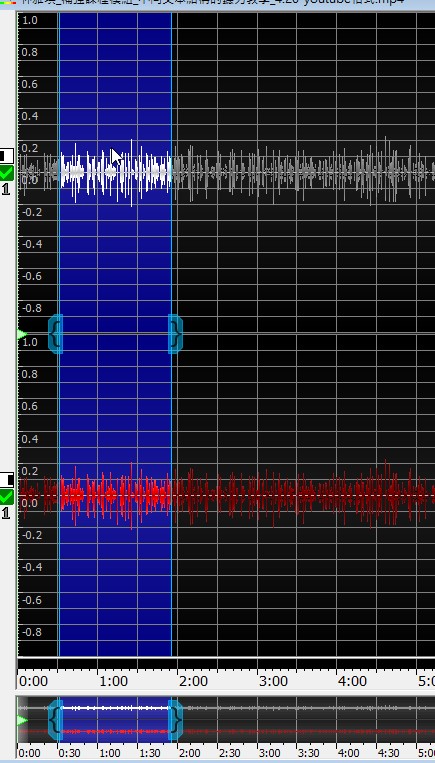
除了使用預設集之外,可以用滑鼠左拉右拉的方式選取一個單純噪音範圍,複製起來
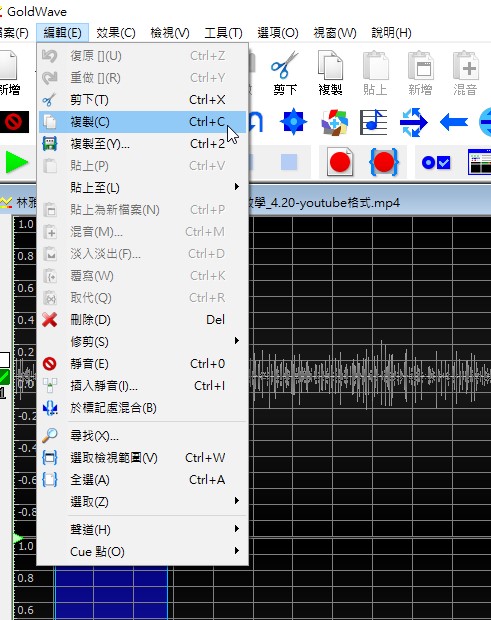
再回到減少雜訊→減少波封,選擇「使用剪貼簿」→預設集「clipboard noise print」
2)調整音量,先選取需要特別處理的範圍
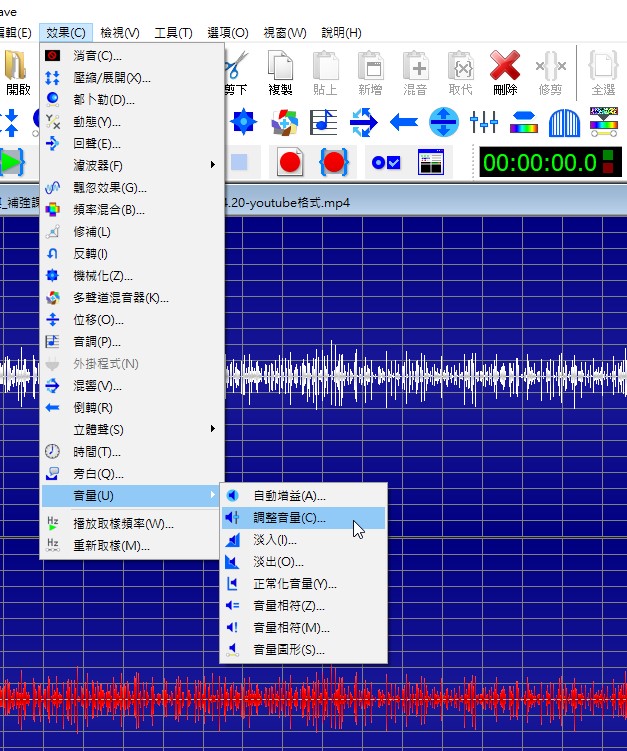
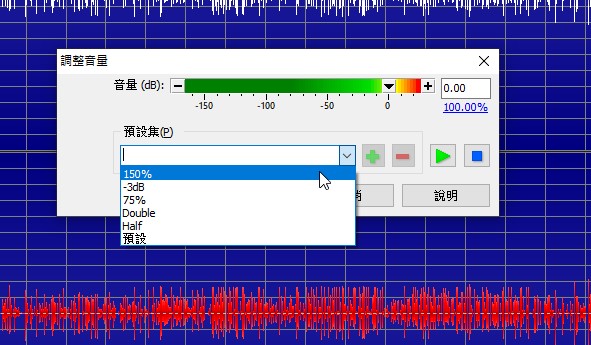
可以直接選預設集的設定值,增加150%或Half(50%)......諸如此類
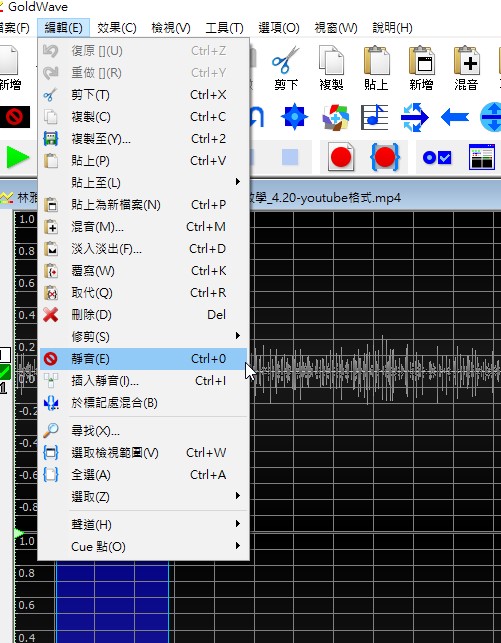
3)消除單純爆音,先選取爆音的範圍再來執行靜音
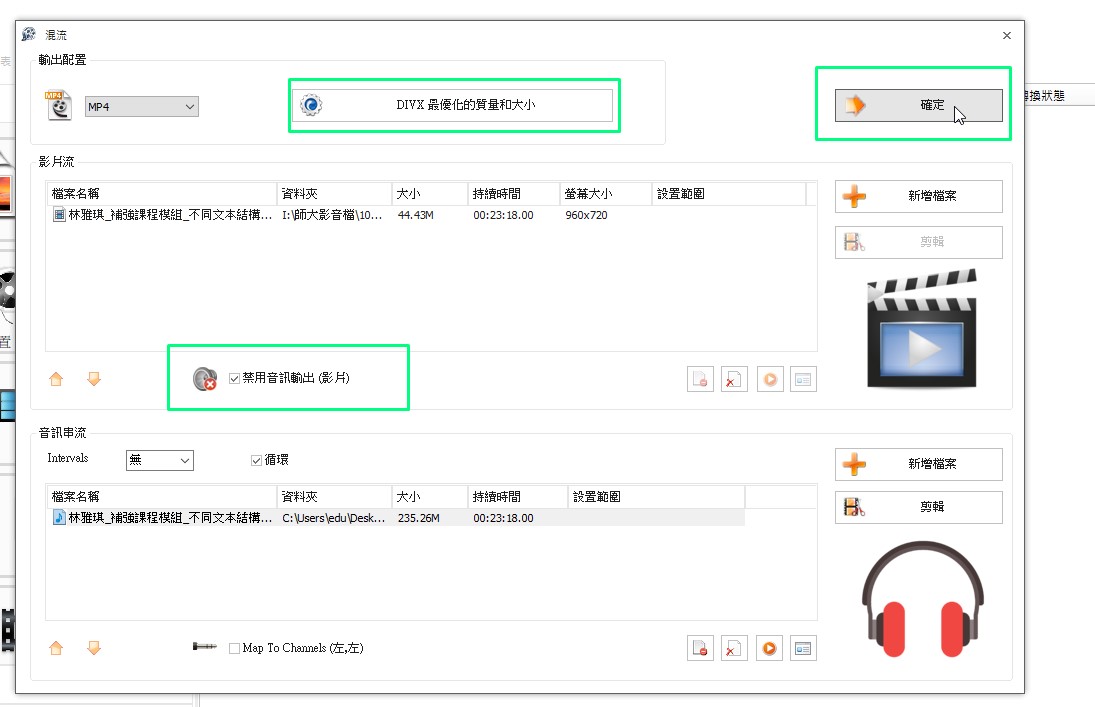
2.FormatFactory合併新的音訊檔+原始的影像檔(不含音訊)→
1)選擇影片-混流
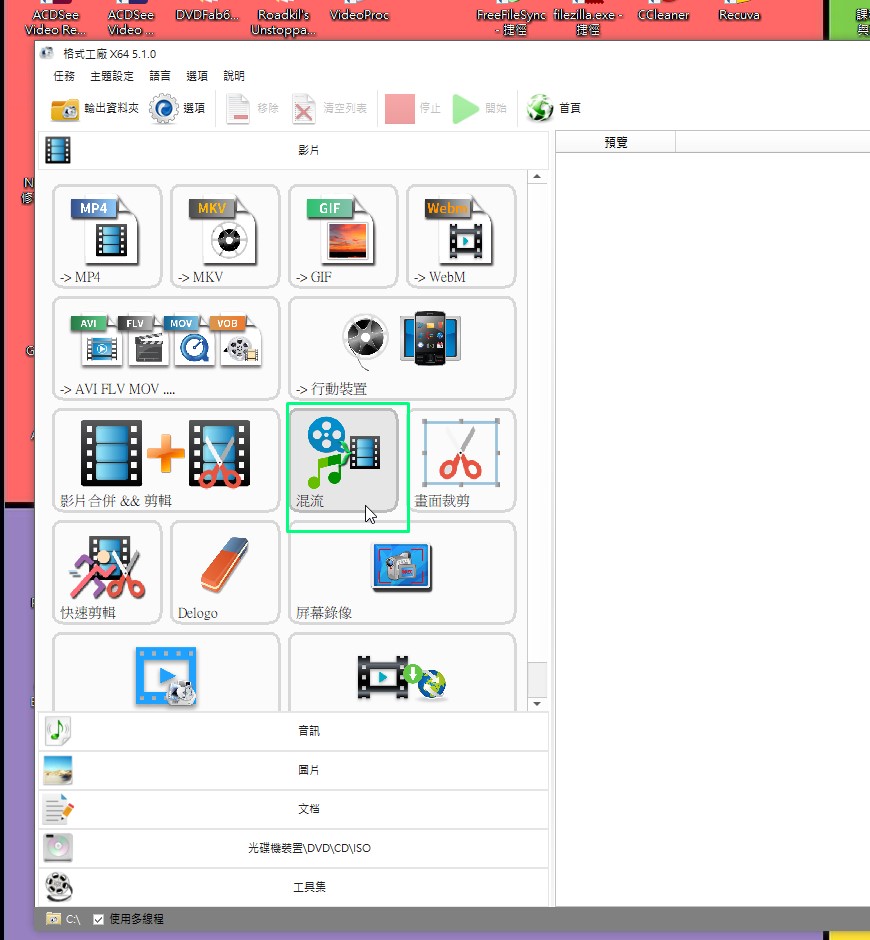
2)選取影像檔,勾選-禁用音訊輸出(影片);選取新的音訊檔;格式設定最優化→確定
3.新的影音檔上傳youtube→
4.下載youtube處理過的影音檔→
1)右邊上方功能列→youtube工作室
2)→左邊功能欄→影片
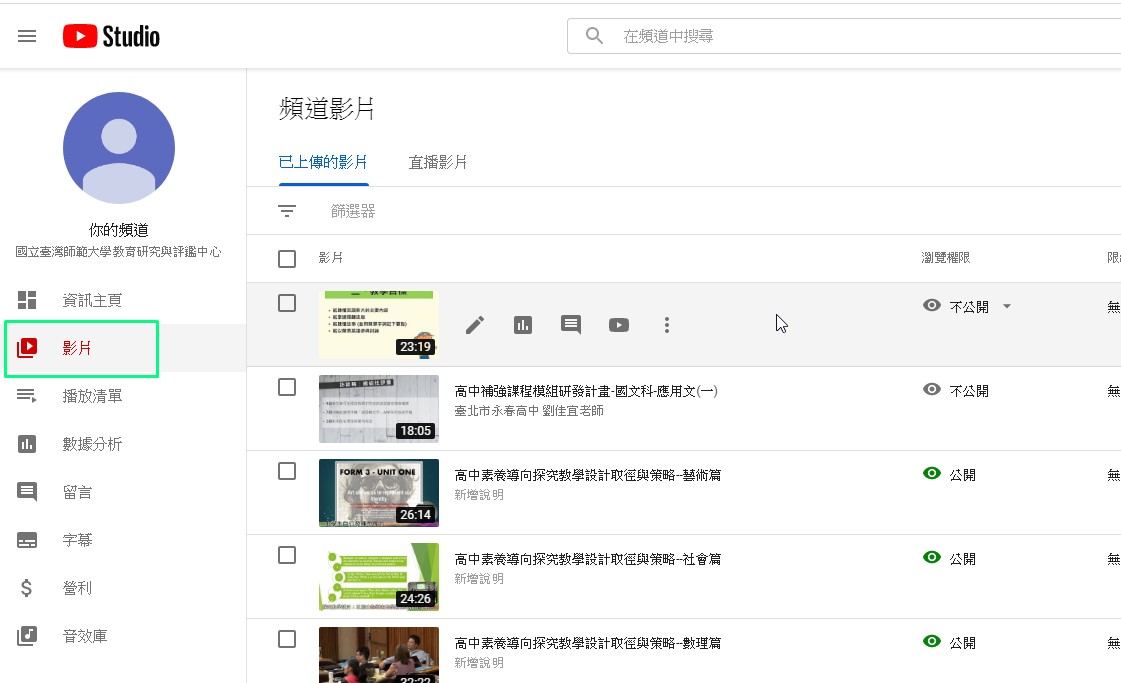
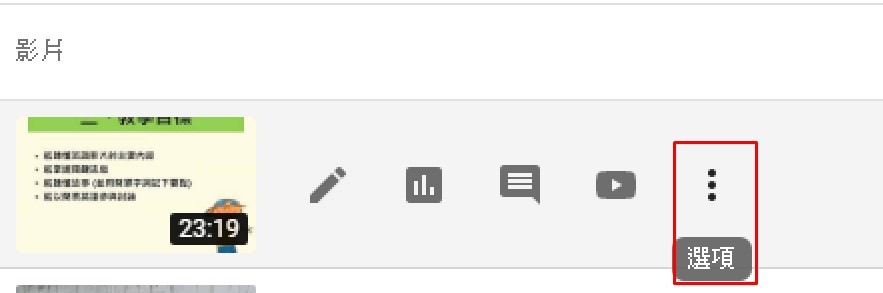
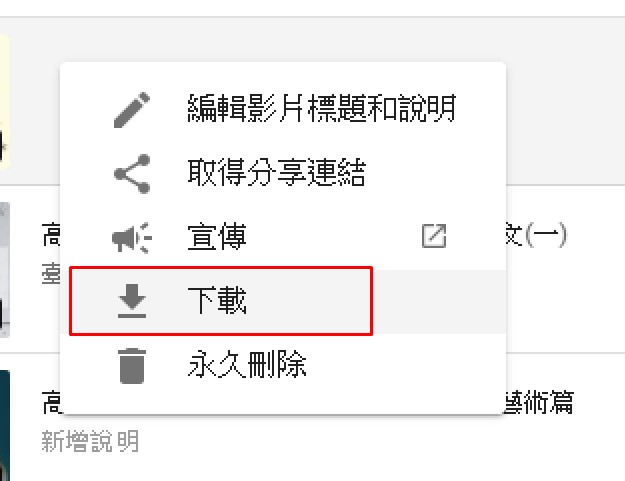
3)→選項→下載
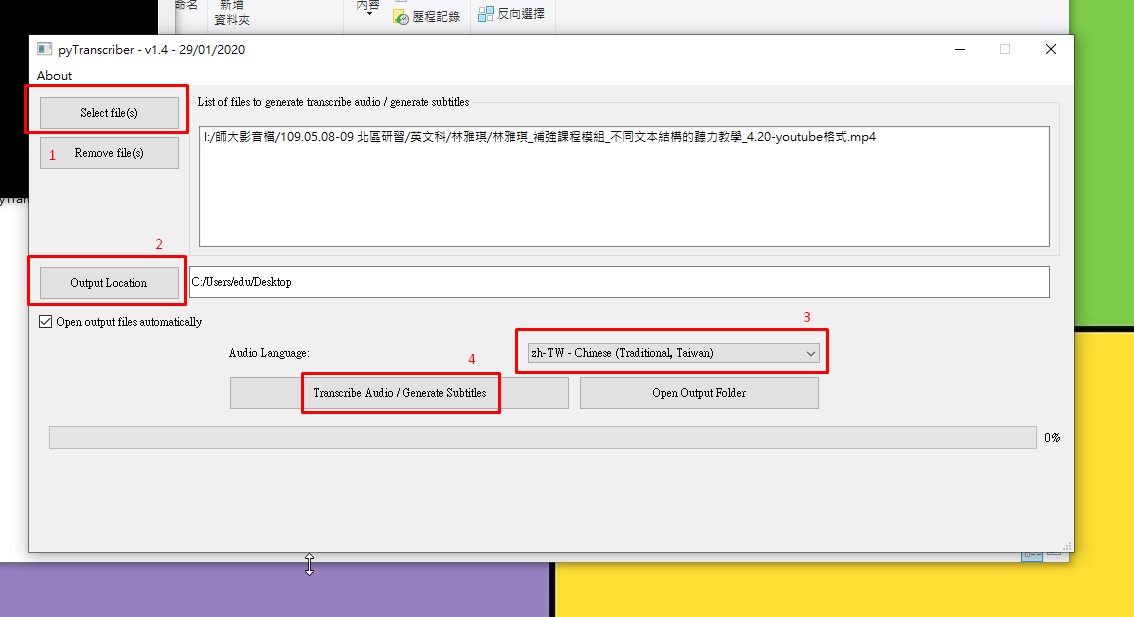
5.pyTranscriber產生字稿→
1)選取檔案
2)輸出的資料夾
3)選取語音種類
4)轉換
5)轉換中
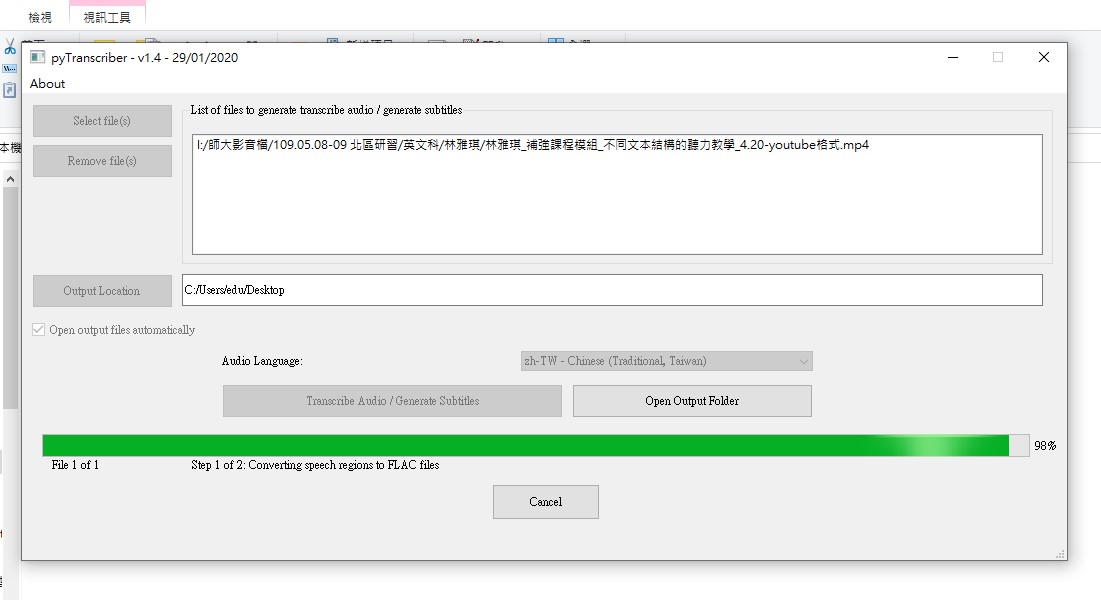
可以看出會先轉成flac格式的音訊檔,但奇妙的是無法直接載入flac檔,只能開啟影音檔如mp4、音訊檔wav、mp3、m4a
6)轉換結束會有兩個檔:srt字幕檔 與 txt純文字檔
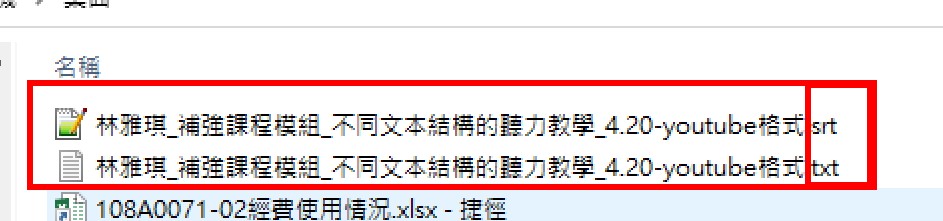
6.Aegisub調整字幕檔→
1)音訊頻譜,框出時間範圍
點滑鼠左鍵,開始時間-紅線
點滑鼠右鍵,結束時間-藍線
可以再用滑鼠微調紅線、藍線的範圍
備註:在音訊頻譜框選範圍之後,要先按一下enter鍵,這樣時間才會修正
2)enter,下一格範圍
3)空白鍵,撥放目前格範圍內的音訊
4)文字編輯區可以修改字幕內容
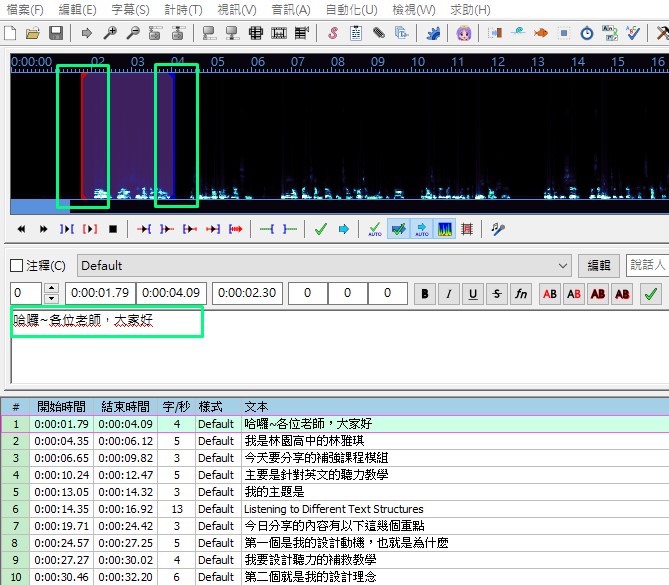
7.上傳字幕檔到youtube
1)跟下載影片的路徑一樣,從youtube工作室→頻道,再點選「字幕」
2)新增字幕,如果已經新增就會是編輯


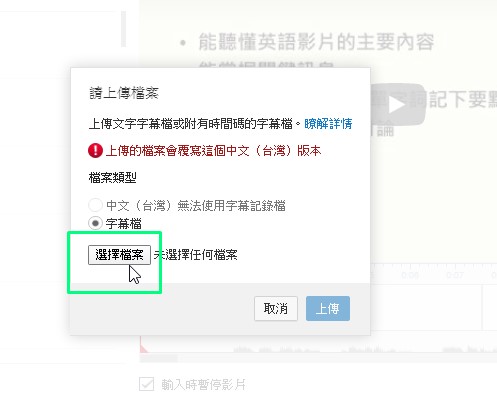
3)上傳字幕檔
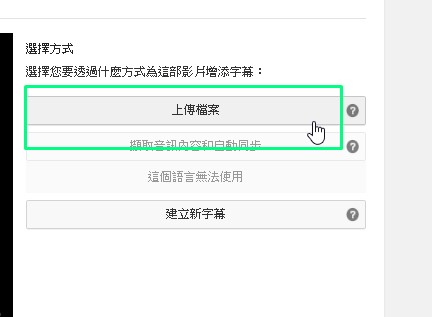
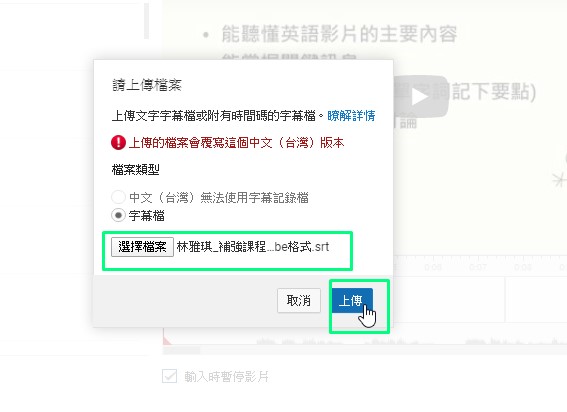
4)選取字幕檔按
5)點選上傳
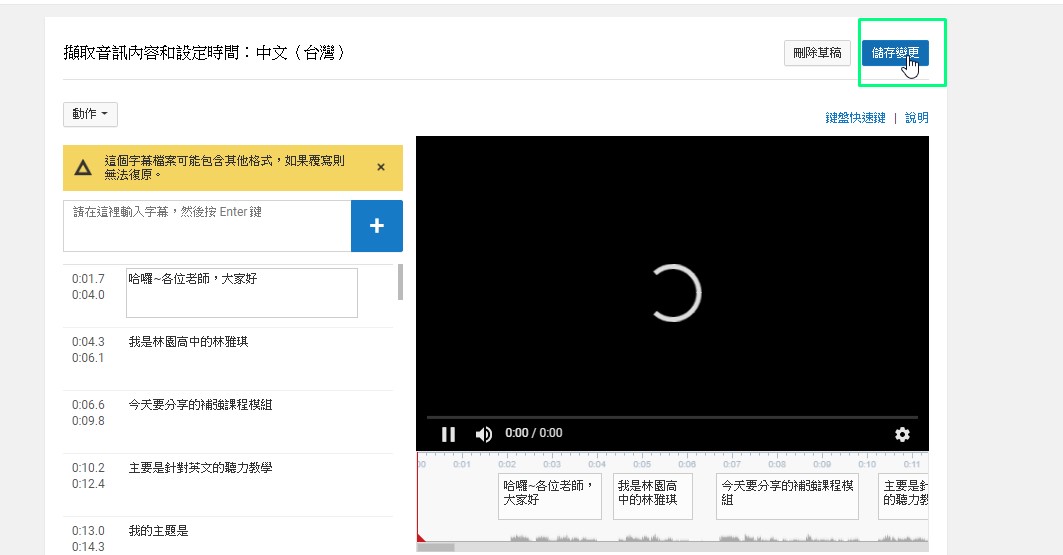
6)儲存變更,刪除草稿會變成編輯,可以繼續編輯
左邊的動作→可以下載字幕檔
◎特殊需求
需要額外合併字幕的影音檔,可以用FormatFactory合併:輸出配置→新增的字幕
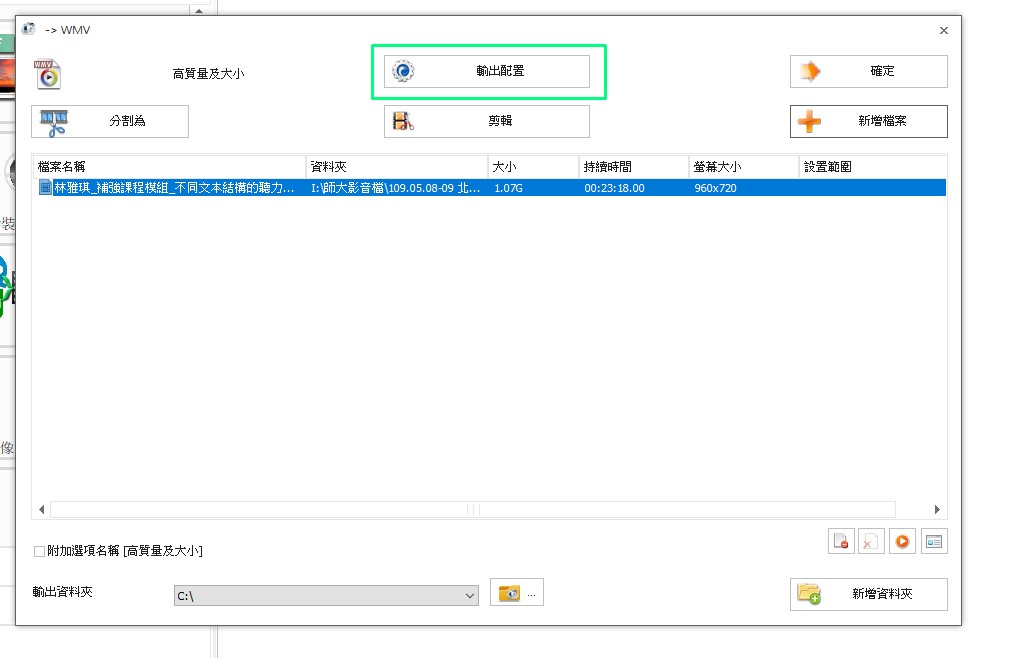
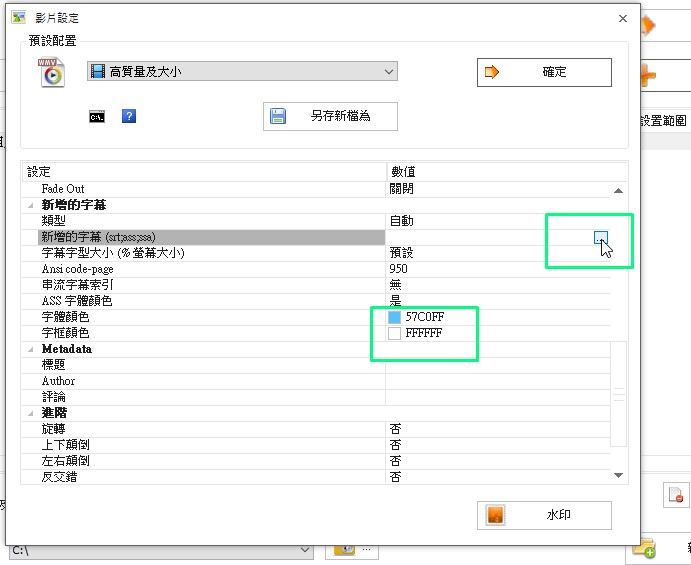
選取新增的字幕檔按,可以設定字體、字框顏色等樣式
◎後記
這個流程屬於事後取得逐字稿的方式,所以會花很多時間在處理文稿與字幕檔的時間調整
但是少了打逐字稿的時間,整體工作時間仍然縮短不少
如果是事前完成的字稿,錄製的過程也基本上照表抄課,在youtube上有看到另一種方式
原理是使用ARCTIME,載入影音檔之後直接匯出字幕檔,可以得到一個只有記錄語音段落的時間記錄ass檔
再配合Notepad++的垂直編輯,將字稿由上而下逐行貼入ass檔內
─因為ass檔是一行一筆資料:時間範圍+文字
─srt檔是一筆資料分成三行:第一行編號、第二行時間範圍、第三行文字
不過這種方式必須語音時間記錄跟字稿段落是一致的,才能一行語音時間段落、自動垂直逐行接續貼上一行字稿
ARCTIME的付費版可以自動語音辨識上字幕,有錢沒時間的人就可以試試這種方式
目前使用google語音辨識的方式,都是透過Chrome內建的Web Speech API函式庫進行線上轉換,所以是不用錢的
google 也有語音辨識的API-Cloud Speech-to-Text,但累計超過60分鐘就會收費
除了要自己寫程式之外,音訊檔也不能用本機端的檔案,一定要存在google的Cloud Storage
突然覺得google是個恐怖的組織~~~~