其實就是透過Python爬資料
今天處理之後要郵寄學校的名單與地址
原始資料是從學校公文系統抓下來的
但是這個系統上面的學校資料不是很完整
有的缺地址、有的缺郵遞區號
猜測可能是因為主要目的在於電子交換
所以這些資訊只是輔助而已
由於在處理的過程中,因為一直用到谷狗搜尋欠缺的地址
所以想說有沒有辦法,用爬蟲的方式取得搜尋結果
之所以會有這個想法是因為谷狗搜尋學校名稱的結果頁面
會在右側出現一個資訊欄位,裡面就有地址資訊
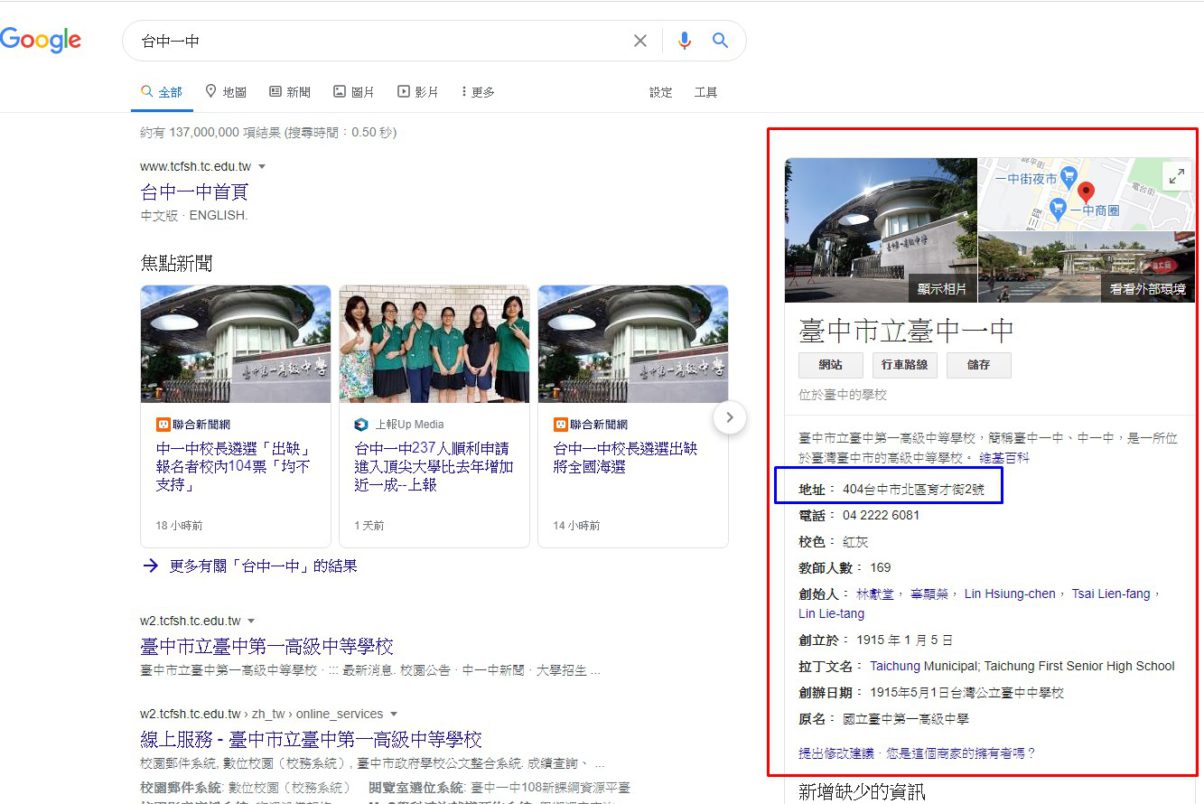
選取地址後,按右鍵-檢查
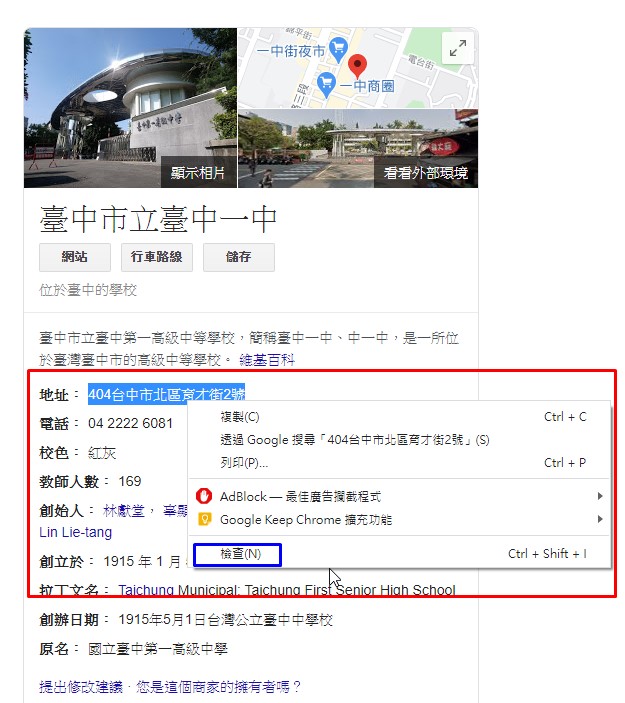
這樣就可以透過chrome知道地址的內容是放在class名稱為 LrzXr的span標籤
其他學校名稱的搜尋結果也是放在同樣的標籤內
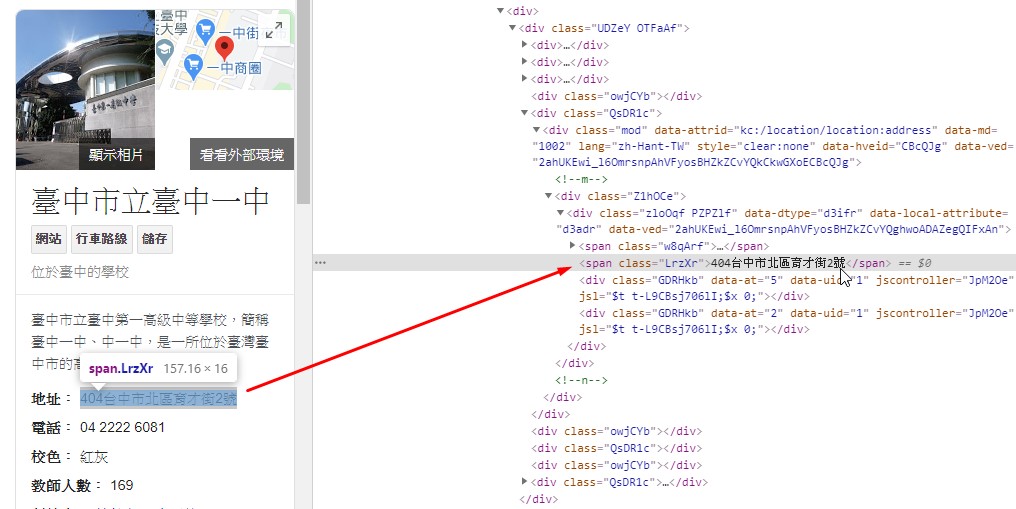
知道這個規則就可以設計爬蟲
腦袋中雖然有這個想法
但是因為要處理的資料量不是很大
再加上覺得自己python的功力不足,可能光是處理這個爬蟲就會花更多的時間
所以還是先靠人力完成之後,再來想怎麼寫程式
這個是最後完成的python程式碼
整體流程為讀取外部資料-關鍵字來源,利用迴圈以及兩個爬資料外掛逐一搜尋與抓取資料,最後再把資料寫入到另一個檔案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# 載入模組 import requests from bs4 import BeautifulSoup #bs4裡的BeautifulSoup類別 import time #讀取資料 f = open("學校.csv","r") #如果檔案編碼是utf-8 要再加上 ,encoding="utf-8" s = f.readlines() # print(type(s)) # print(s[2]) # print(len(s)) #s[] 會包含第一筆-欄位名稱 # 設定輸出字串的第一行文字 add="學校,地址\n" for i in range(1,len(s)) :#假設連欄位名稱共10筆→s[0]~s[9],而s[0]是欄位名稱,所以實際資料是9筆=範圍range(1,10)=range(1,len(s)) s_name=s[i].strip("\n") #s_name為讀取到的關鍵字 除掉後面的空格 # requests.get("網址") + 關鍵字 url='https://www.google.com/search?q='+s_name headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"} html = requests.get(url, headers=headers) # BeautifulSoup(html.text, "html.parser") sp = BeautifulSoup(html.text, "html.parser") # sp.find_all("標籤","屬性") 找出帶有這些標籤的資料 # 處理例外情況 if i < len(s)-1: #如果不是最後一筆才加分行符號 try: list1 = sp.find_all("span","LrzXr") add += "{},{}\n".format(s_name,list1[0].text) #地址是第一個LrzXr → list1[0] 累加輸出字串 except: # 抓不到資料,就輸出查無資料,並且跳到下一個迴圈 add +="{},{}\n".format(s_name,"查無資料") continue else: try: list1 = sp.find_all("span","LrzXr") add += "{},{}".format(s_name,list1[0].text) #地址是第一個LrzXr → list1[0] 累加輸出字串 except: # 抓不到資料,就輸出查無資料,並且跳到下一個迴圈 add +="{},{}".format(s_name,"查無資料") continue #print(add) time.sleep(2) #間隔2秒再繼續下一個迴圈 #print(add) #寫出資料 fw=open("地址.txt","w","encoding="utf-8") #將抓到的資料以utf-8編碼寫出 fw.write(add) fw.close() print("完成") |
爬資料主要是透過 requests 跟 BeautifulSoup4 這兩支外掛
1.requests 取得資料
因為谷狗,或者說大部分網站都是不允許透過程式大量搜尋資料
所以必須讓網站覺得這是透過瀏覽器進行的搜尋
於是必須傳遞Headers訊息,其中至少要有 user-agent
輔助使用 time 外掛設定間隔時間,讓後面不會因為跑迴圈的關係一下子傳出太多請求而被擋
2.BeautifulSoup4讀取requests 取得的資料
這裡就是透過之前找到的html標籤來確定資料的位置
由於不只一個資料欄位使用 class名稱為 LrzXr的span標籤
但是還好地址都是在第一筆,所以也沒造成困擾
3.補充說明1
在測試過程中也曾經想要用另一種方式-利用selenium-webdriver控制chrome
再取得網頁的html資料,不過股狗搜尋可以直接在網址 https://www.google.com/search?q= 加上關鍵字就可以搜尋
也就沒必要額外用控制瀏覽器的方式來輸入關鍵字
4.補充說明2
輸出的結果
add += "{},{}\n".format(s_name,list1[0].text)
用到 累加字串 的設定
在前面第13行 設定add第一行的資料
後面的搜尋結果利用格式化字串呈現 學校 , 地址 的格式存入add內
5.補充說明3
也曾經測試
5-1如果是搜尋結果不會有右側資訊欄,這時候會發生什麼情況??
5-2其他非學校名稱的關鍵字搜尋,如果搜尋結果有右側資訊欄,這時候會抓到什麼資料??
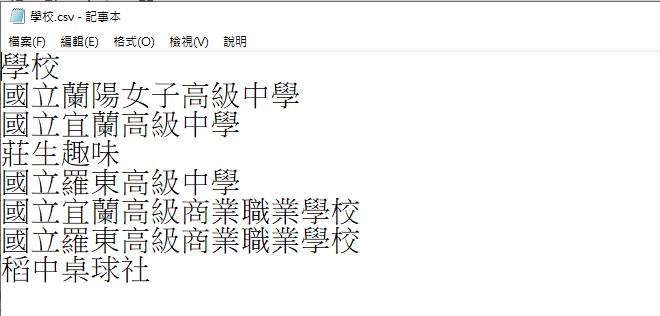
要搜尋的資料 學校.csv的內容
5-1 的結果,如果沒有右側資料欄當然是會造成錯誤
因為會抓不到資料會讓list1 = sp.find_all("span","LrzXr")的list1是空的串列,無資料 list1=[ ]
這樣連帶會造成後面的格式化字串出錯add += "{},{}\n".format(s_name,list1[0].text)
於是用 try: except: +continue的方式來處理例外情況
5-2如果是有右側資訊欄的其他關鍵字搜尋
同樣會抓到第一個class名稱是LrzXr的 span標籤內的資料
搜尋結果-地址.csv的內容
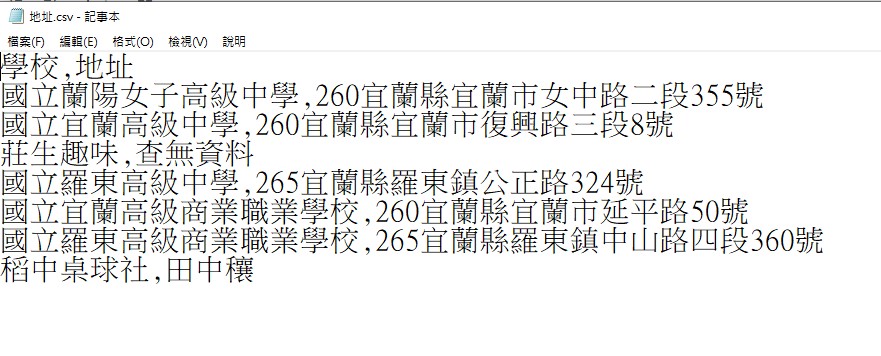
6.補充說明4
後來發現會因為最後一筆結尾會有換行符號
因此透過 If else判斷是否為最後一筆
如果是最後一筆,就不輸出換行符號