原本是透過Python 跟 selenium-webdriver抓取Html
但是後來網頁原始檔都變成JavaScript程式碼
影片資訊是寫在< meta name='description' content='影片資訊'>
於是改變搜尋的方式
利用 find_element_by_xpath 定位搜尋頁面元素
tagX = browser.find_element_by_xpath("//meta[@name='description']") # meta標籤 name屬性值為'description'的元素
#tag = browser.find_element_by_id('description') #資訊所在的DIV id 現在不能直接抓Html
#print(tagX.get_attribute("content")) #取出其中的content屬性值
tag = tagX.get_attribute("content")
tag2 = tag.replace('\n','').replace('\r','') #用空字串取代所有換行符號 ,不能用strip刪除
#tag2=tag.text.replace('\n','').replace('\r','') #用空字串取代所有換行符號 ,不能用strip刪除
這次是要抓之前計畫放在youtube示例影片的介紹資訊
其實也是透過Python來爬資料
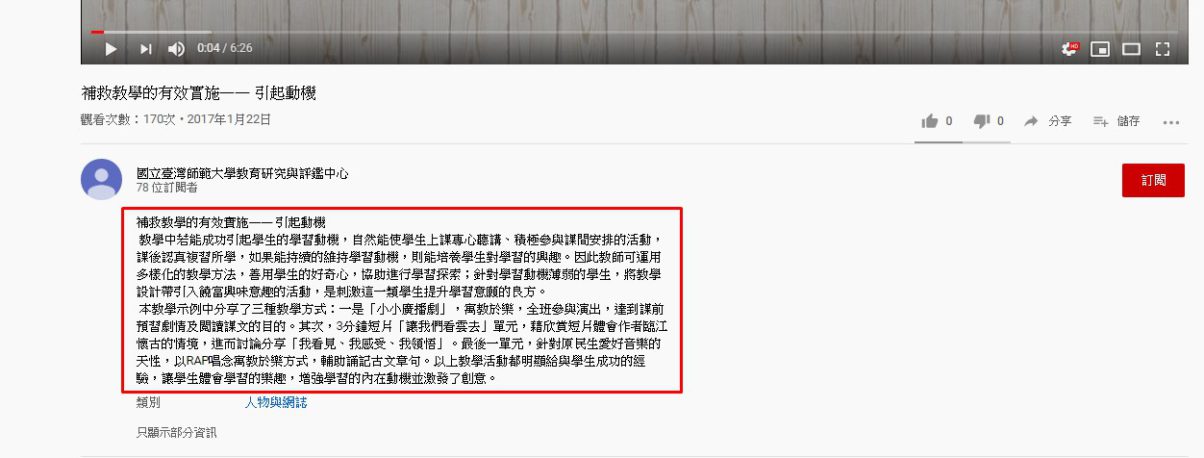
由於youtube很多內容是寫在JavaScript裡
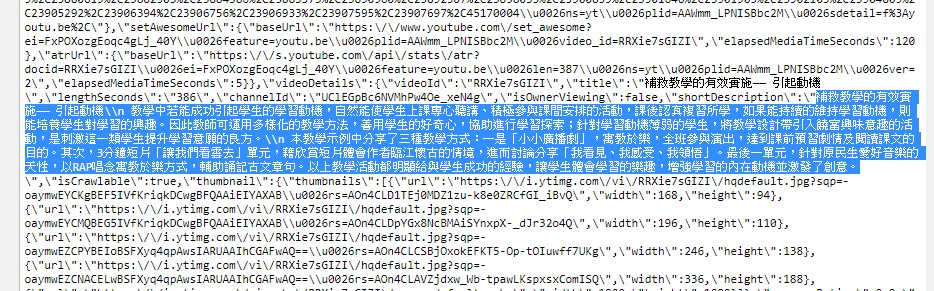
用內容-檢查的方式找到的html標籤是 id名稱為 description的DIV
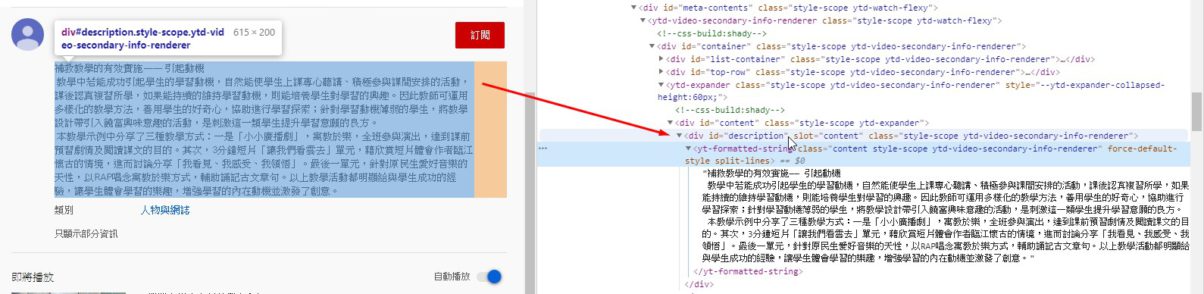
如果是用requests 跟 BeautifulSoup會爬不到這個DIV
嘗試抓取script
只能抓到整個script,之後的資料清理就會卡住
應該也有抓取、清理JavaScript資料內容的方式
因為其實內容是 json的格式
但是我還沒找到看得懂的教學,之後再嘗試看看
於是改用selenium-webdriver的方式
先讓瀏覽器載完html資料之後,這樣就能順利抓到內容資訊所在的DIV
完成之後的程式碼如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
from selenium import webdriver import time #chromedriver.exe執行檔所存在的路徑 須配合電腦上的chrome版本 # chrome_path =r"C:\Users\trico\Desktop\chromedriver\chromedriver.exe" chrome_path =r"D:\chromedriver_win32\chromedriver.exe" options = webdriver.ChromeOptions() #透過options紀錄webdriver.ChromeOptions()的設定 options.add_argument("--headless") #增加啟動參數,瀏覽器頁面不可視化(背景執行) browser = webdriver.Chrome(chrome_path,options=options) #webdriver.Chrome的設定選項 # browser = webdriver.Chrome(chrome_path) #讀取資料 f = open("url.csv","r") #如果檔案編碼是utf-8 要再加上 ,encoding="utf-8" s = f.readlines() c = "科目,示例名稱,網址,介紹\n" #設定寫出檔案的第一行 for i in range(1,len(s)): url=s[i] list=url.split(",") #分割串列 # print(list[2].replace('\n','')) #第3筆是最後1筆資料會有換行符號,須去掉 browser.get(list[2].replace('\n','')) #載入網址 time.sleep(3) #等待3秒載入網頁 tag = browser.find_element_by_id('description') #資訊所在的DIV id tag2=tag.text.replace('\n','').replace('\r','') #用空字串取代所有換行符號 ,不能用strip刪除 # print(tag2) # print(len(tag2)) # 因為沒有資訊也同樣能抓到空字串,不會出現錯誤 # try: # tag = browser.find_element_by_id('description') # tag2=tag.text.replace('\n', '').replace('\r', '') # c +="{},{},{},{}".format(list[0],list[1],list[2],tag2) # print(c) # except: # c +="{},{},{},{}".format(list[0],list[1],list[2],"無說明") # continue # print(c) # 改用 if判斷 len(tag2)是否>0 if i < len(s)-1: #如果不是最後一筆才加分行符號 if len(tag2) > 0 : #print(tag2) c +="{},{},{},{}\n".format(list[0],list[1],list[2].replace('\n',''),tag2) else: tag2="無內容資訊" c +="{},{},{},{}\n".format(list[0],list[1],list[2].replace('\n',''),tag2) #print(tag2) else: if len(tag2) > 0 : #print(tag2) c +="{},{},{},{}".format(list[0],list[1],list[2].replace('\n',''),tag2) else: tag2="無內容資訊" c +="{},{},{},{}".format(list[0],list[1],list[2].replace('\n',''),tag2) #print(tag2) #寫出資料 fw=open("c.txt","w",encoding="utf8") fw.write(c) fw.close() #print(c) browser.close() #關閉 瀏覽器 print("完成") |
除了 selenium-webdriver之外,也用到time外掛程式來設定間隔時間,讓網頁有時間可以載入
selenium本身也是可以設定等待時間,但是我看不懂說明
於是還是土法煉鋼讓程式直接停止3秒再繼續
細節都寫在程式碼註解了,整體流程大致有四個部分
1.透過 selenium-webdriver 載入網頁並下載頁面原始檔
url.csv的資料結構,網址是第3欄 ( list[2] )
2.利用browser.find_element_by_id取得內容資訊所在的DIV
3.取出資料內容與資料清理
取出的字串有很多換行符號,一開始使用strip的方式來刪除,但都是失敗
後來谷狗大神說字串內只能取代,於是用replace的方式將所有換行符號取代為空字串
4.寫出資料
python在windows系統寫出檔案時,是透過cmd(命令提示字元)執行,而cmd預設的編碼是ANSI
所以當寫出的字串之中有無法在ANSI編碼時,寫出就會出現錯誤
比較好的方式是以UTF-8編碼寫出資料
但是,如果寫出檔案採用CSV,並且用excel開啟時就會出現亂碼
同樣是因為excel預設ANSI編碼
解決方式有3種
4-1用記事本另存成ANSI,再用excel開啟
4-2不要直接用excel開啟,而是先開新的excel空白活頁簿,再到資料分頁→取得外部資料-從文字檔,再依據匯入字串精靈的引導步驟匯入
4-3直接寫出純文字檔(*.txt)再用記事本開啟,或者用記事本開啟csv檔