這個版本是修改自Gg / 從Google Spreadsheets建立查詢ISBN的AppSheet APP
原本抓取回來的Html資料的是透過外加資料庫 Cheerio來處理
但是日前在彰化一整天的粉絲團看到有類似教學文
對於Html的處理方式只用了javascript內建函式
indexOf() 分別取得特定字串的第一個字元數
substring() 在字串中擷取特定範圍的內容
replace(/(<([^>]+)>)/ig,' ') 配合正規表達式將所有的html標籤轉換成空字串
replace(/\n/g,' ') 將換行符號轉換成空白
分別組成兩個外部function處理Html資料並取得想要的內容
整體而言,程式碼分為3個部分
1.取得Html資料
2.取出特定範圍的字串
3.去除html標籤
以下分別說明這3個部分應該注意的地方
1.主程式-取得Html資料
這個部分的程式碼沒有更動
同樣是透過UrlFetchApp.fetch()取得網頁內容
然後將資料送到外部程序進行處理
2.取出特定範圍的字串
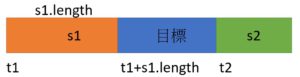
這裡要先掌握目標網頁的Html架構
以及目標內容的前後標籤,這樣才能正確設定範圍取出字串
這個流程類似之前在VBA處理JSON格式資料的方式
也就是切割內容找到目標資料
indexOf() 可以取得特定字串的第一個字元數
如果加上第2個參數,表示從特定位置開始尋找
function get_content(s,s1,s2){ // s-取得的Html資料 s1-在目標資料前面的Html標籤 s2-在目標資料後面的Html標籤
//indexOf()取得起、迄字串的第一個字元所在
var t1=s.indexOf(s1);
var t2=s.indexOf(s2,t1+1); //從t1+1的位置開始找 也就是從S1之後開始找
//Logger.log(s.substring(t1 + s1.length, t2))
//substring()擷取字串範圍
return s.substring(t1 + s1.length, t2); // t1 + s1.length 在目標資料前面的Html 最後一個字元的位置
}
當知道目標範圍前後標籤的位置
就可以利用substring() 擷取特定範圍的內容
因為每一筆目標資料都要經過相同的程序
所以將這個程序獨立成外部程序
備註:後來發現不同ISBN查詢的結果頁面
項目內容可能不太一樣
所以會有的項目在indexOf()是搜尋不到對應結果,得到數值 -1的結果
因此再用一個判斷式來處理
function get_content(s,s1,s2){
//indexOf()取得起、迄字串的第一個字元所在
var t1=s.indexOf(s1); //查找不到,則回覆 -1
if(t1 != -1){
var t2=s.indexOf(s2,t1+1); //從t1+1的位置開始找 也就是從S1之後開始找
//Logger.log(s.substring(t1+s1.length,t2))
//substring()擷取字串範圍
return s.substring(t1 + s1.length, t2);
}else{
return "無此項目";
}
}
3.去除html標籤
在2的程序會得到特定範圍的Html資料
因為要取得的資料其實不用這些標籤
只需要留下文字內容
所以再透過replace()與正規表達式去除有標籤的部分,以及不必要的空白
整體程式碼
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
function isbnQuery2() { var sheet= SpreadsheetApp.getActiveSpreadsheet(); var sh= SpreadsheetApp.openById("1BMajZnG64K8pUXEBtaTEZF0fEIqiN4JmFuJGZ4U1doU"); //https://docs.google.com/spreadsheets/d/1BMajZnG64K8pUXEBtaTEZF0fEIqiN4JmFuJGZ4U1doU/ var sheet =sh.getSheets()[0]; var lastRow = sheet.getLastRow(); var isbn = sheet.getRange(lastRow,1).getValue(); //9789865026578 var url = "http://192.83.186.170/search*cht?/i"+ isbn +"/i"+ isbn +"/0,0,0/frameset&FF=i"+ isbn; var hData = UrlFetchApp.fetch(url); var rowData = hData.getContentText();//儲存抓回的內容 var rowRe = hData.getResponseCode(); Logger.log(rowRe); //Logger.log(rowData); if(rowRe >= 200 || rowRe < 400){ //著者 var author = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">著者</td>","</a>")); Logger.log(author); //題名 var title = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">題名</td>","</strong></td></tr>")); Logger.log(title); //版本項 var version = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">版本項</td>","</td></tr>")); Logger.log(version); //出版項 var publisher = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">出版項</td>","</td></tr>")); Logger.log(publisher); //面數高廣 var size = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">面數高廣</td>","</td></tr>")); Logger.log(size); //國際標準書號 var pisbn = stripHTML(get_content(rowData,"class=\"bibInfoLabel\">國際標準書號</td>","</td></tr>")); Logger.log(pisbn) }else{ Logger.log("error") } } //--------------------------------------------------------取出特定範圍的字串 s-html s1-起 s2-迄 function get_content(s,s1,s2){ //indexOf()取得起、迄字串的第一個字元所在 var t1=s.indexOf(s1); //查找不到,則回覆 -1 if(t1 != -1){ var t2=s.indexOf(s2,t1+1); //從t1+1的位置開始找 也就是從S1之後開始找 //Logger.log(s.substring(t1+s1.length,t2)) //substring()擷取字串範圍 return s.substring(t1 + s1.length, t2); }else{ return "無此項目"; } } //--------------------------------------------------------去除html標籤 function stripHTML(input) { //Logger.log(input) var output = ''; if(typeof(input)=='string'){ output = input.replace(/(<([^>]+)>)/ig,'');//將所有的html標籤轉換成空字串 } output=output.replace(/\n/g,'');//取代換行成空白 //Logger.log(output) return output; } |