在前一篇提到:Python Json模組中dumps()、loads()、dump()、load()
讀取資料:loads() 、 load()
寫出資料:dumps()、dump()
差別在於有s的都是讀取或寫出字串型態,所以都是在程式中使用
沒有s的都是讀取或寫出Json檔案,所以要留意編碼格式
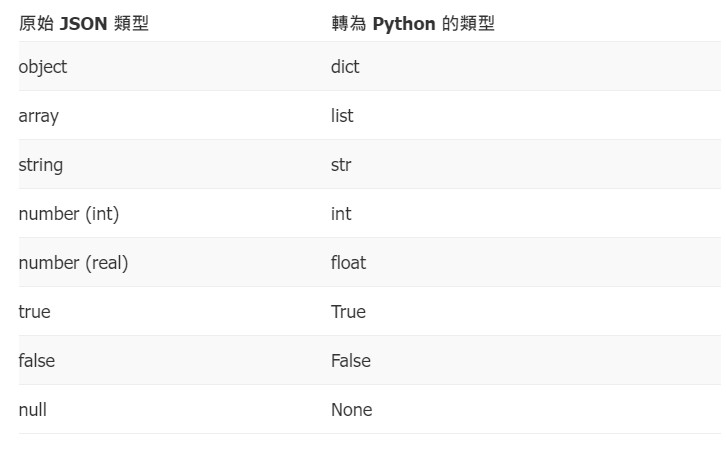
原始JSON檔案跟在Python轉換的關係如下
現在來實作這幾個函式的實際運用
資料來源是政府公開資訊的各鄉鎮市區人口密度-109各鄉鎮市區人口密度
import requests,json
html = requests.get("https://od.moi.gov.tw/api/v1/rest/datastore/301000000A-000605-059")
#print(type(html.text)) #<class 'str'>
使用loads()解析來自requests模組取得的字串資料,轉換之後的json資料對應格式是dict字典
dict1=json.loads(html.text)
dump()轉存成本機檔案
f2=open("109people.json",mode="w",encoding="utf-8") #建立109people.json 寫出模式
json.dump(dict1, f2, indent = 4, ensure_ascii=False) #寫出資料
f2.close()
解析json資料取出需要的內容,再存成本機檔案
使用dict.get()取得指定key值的資料
而records存放的資料為陣列型態(在python則是串列型態)
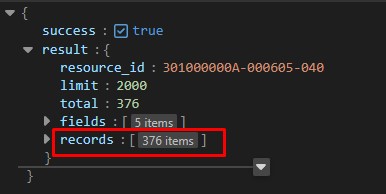
dict2=dict1.get("result") #取出 key值為 result的資料
list1=dict2.get("records") #取出 key值為 records的資料
創建新的字典,新增 key值為 records,value值為前面取出的串列資料
dict3={}
dict3["records"]=list1
dump()轉存成本機檔案,ensure_ascii=False避免轉譯成ASCII
f3=open("109people_records.json",mode="w",encoding="utf-8") #建立109people_records.json寫出模式
json.dump(dict3, f3, indent = 4, ensure_ascii=False) #寫出資料
f3.close()
dumps()轉換成python的字串資料,ensure_ascii=False避免轉譯成ASCII
json.dumps(dict3, ensure_ascii=False)
load()讀取本機檔案,再用dump()轉存為新的本機檔案,indent設定內縮幾個字元,ensure_ascii=False避免轉譯成ASCII
import json
f=open("109people.json",mode="r",encoding="utf-8") #開啟本機檔案
#2.解析JSON
dict1=json.load(f)
f2=open("109output.json",mode="w",encoding="utf-8") #建立109output.json 寫出模式
json.dump(dict1, f2, indent = 4, ensure_ascii=False) #寫出資料
f2.close()